智汇华云eBPF介绍与使用

Linux在日常的使用中已经无处不在了,从人们的手机,到电视机,再到路由器,都运行在linux内核之上,而eBPF就是Linux内核的一把瑞士军刀,通过eBPF可以在linux内核中运行程序,运维人员可以使用它对linux内核进行监控,开发者可以使用它对linux内核功能进行定制修改,做到很多以前无法实现的功能。
的说法! eBPF is a revolutionary technology with origins in the Linux kernel that can run sandboxed programs in an operating system kernel。
个人认为,简单的说,eBPF可以理解为一个框架,通过这个框架,我们可以在内核中执行自己编写的程序代码。
eBPF基本概念
eBPF的前身是BPF(extended Berkeley Packet Filter),BPF是内核中用来做高效过滤网络报文的,tcpdump里面就是用的BPF技术过滤报文。2014年内核3。18中eBPF第一次出现,此时的eBPF已经成为内核的顶级子系统,演进为一个通用执行引擎,允许用户在内核中运行自己的程序。
挂载点(Hook)eBPF程序基于事件触发,当内核代码走到对应的挂载点就会执行挂载在此处的eBPF程序。常见的挂载点有:系统调用,内核函数进入/退出,内核跟踪点,网络数据包等等。
映射(Maps)eBPF程序中用来存储数据,共享数据的结构体就是Maps,内核内置了多种类型的Maps给开发者使用,常见的有哈希表,数组,LRU,Ring buffer等等。
帮助函数(Helper Calls)内核为了保证安全,运行在内核中的eBPF程序只能调用当前内核版本预定义好的函数,不能随意调用其他内核函数,函数名称都是以bpf_开头命名。例如u32 bpf_get_smp_processor_id(void),可以获取当前eBPF程序运行在哪个cpu上。
加载与验证(Loader &; Verification)编写好的eBPF程序需要先通过编译,生成字节码,之后通过调用bpf系统调用将字节码加载到内核,此时内核会运行自己的验证器来检验eBPF程序,确保程序是安全的,有限循环的,不会把linux系统搞坏。
eBPF特点
强大的内核可编程性。随着内核版本的升级,内核中可以运行eBPF程序的地方越来越多,eBPF可以做的事情也越来越多。不同内核功能加入eBPF版本列表:
XDP(快速数据路径)Kernel 4。8
LIRC(红外)Kernel 4。18
限制100万条指令Kernel 5。2
Socket lookup(控制数据包入socket)Kernel 5。9
开发方便开发者不需要自己定义数据结构,直接使用现成的Maps进行存储共享数据,只需要关注具体的业务实现代码。由于eBPF程序先编译成字节码,之后内核自己校验通过之后再生成可用的内核代码,所以可以一次编译处处运行,不需要像内核模块一样,每次更新内核之后都要重新编译。
可以在x86上编译mips架构上运行的eBPF字节码。免去交叉编译的痛苦。
安全数据操作都是通过Maps,操作Maps的函数也是预先定义好的,不存在访问空指针。
eBPF使用
介绍了这么多eBPF的概念,接下来实际操作一下,看看eBPF程序如何编译和使用,这里采用原汁原味的linux源代码编译演示。
使用最新的archlinux系统,其他系统也差不多,稍微按照实际情况改一下。
# asp checkout linux# 准备linux内核源码
# makepkg -o -d –skippgpcheck# 下载linux源代码
# make mrproper
fig
# make headers_install
# make modules_prepare
# make VMLINUX_BTF=/sys/kernel/btf/vmlinux M=samples/bpf
# asp checkout linux# 准备linux内核源码
# makepkg -o -d –skippgpcheck# 下载linux源代码
# make mrproper
# zcat /proc/config。gz >;。config
# make headers_install
# make modules_prepare
# make VMLINUX_BTF=/sys/kernel/btf/vmlinux M=samples/bpf
这里把内核自带的bpf示例程序都编译出来了,在目录samples/bpf下面。
这里我们具体看一个sampleip的eBPF程序,看看eBPF程序是如何编写的
直接上代码:
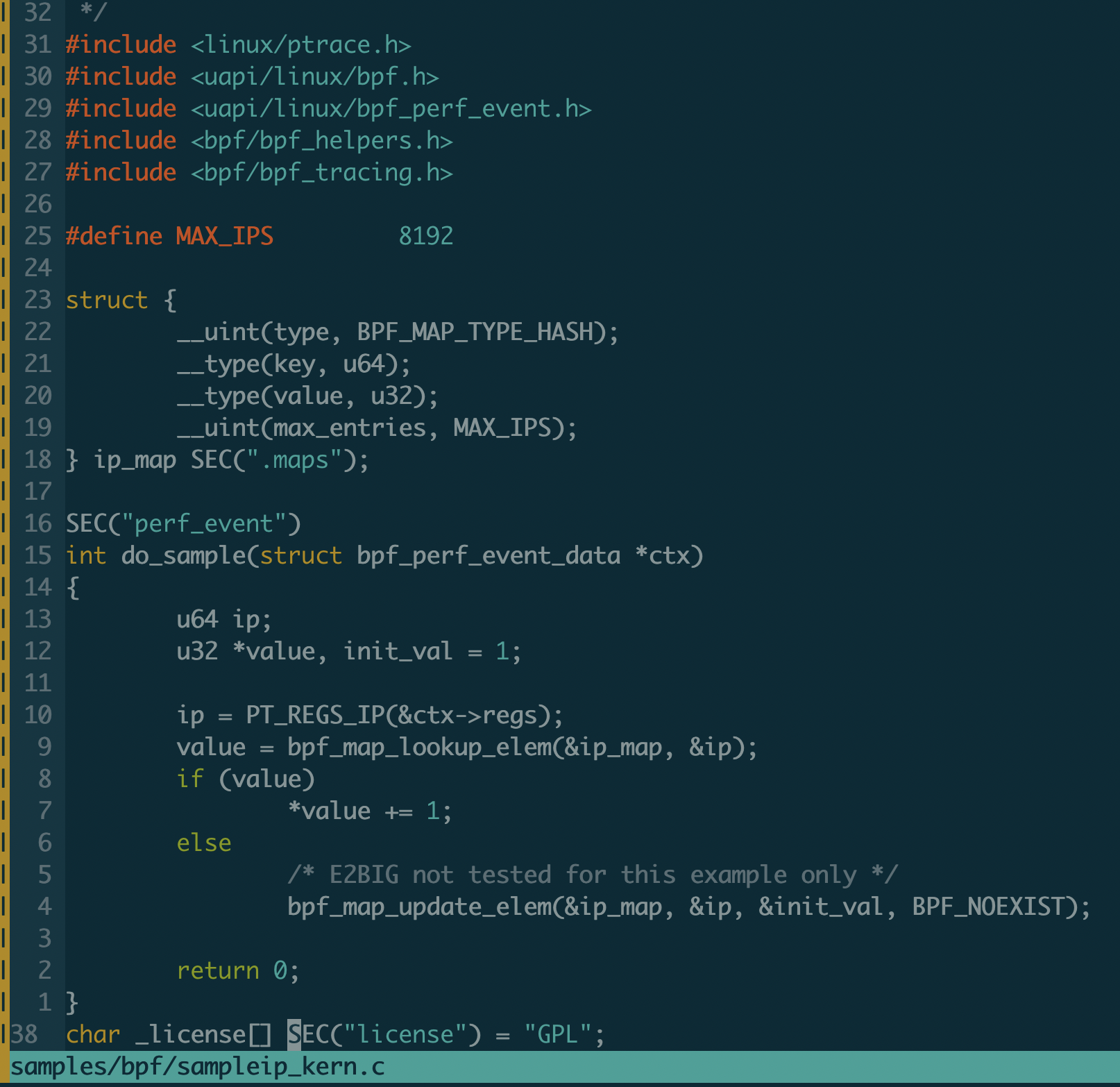
首先17到23行定义了一个maps,叫ip_map,类型是哈希,键是u64,值是u32,最大长度8192。
之后定义了一个do_sample函数,函数参数类型是bpf_perf_event_data,里面有当前内核IP指令指针寄存器的内容。通过调用bpf_map_lookup_elem函数来更新ip_map。
运行内核编译好的sampleip程序,默认是采样5秒,每秒采样99次,程序结束后会把ip_map采集到的信息打印出来。
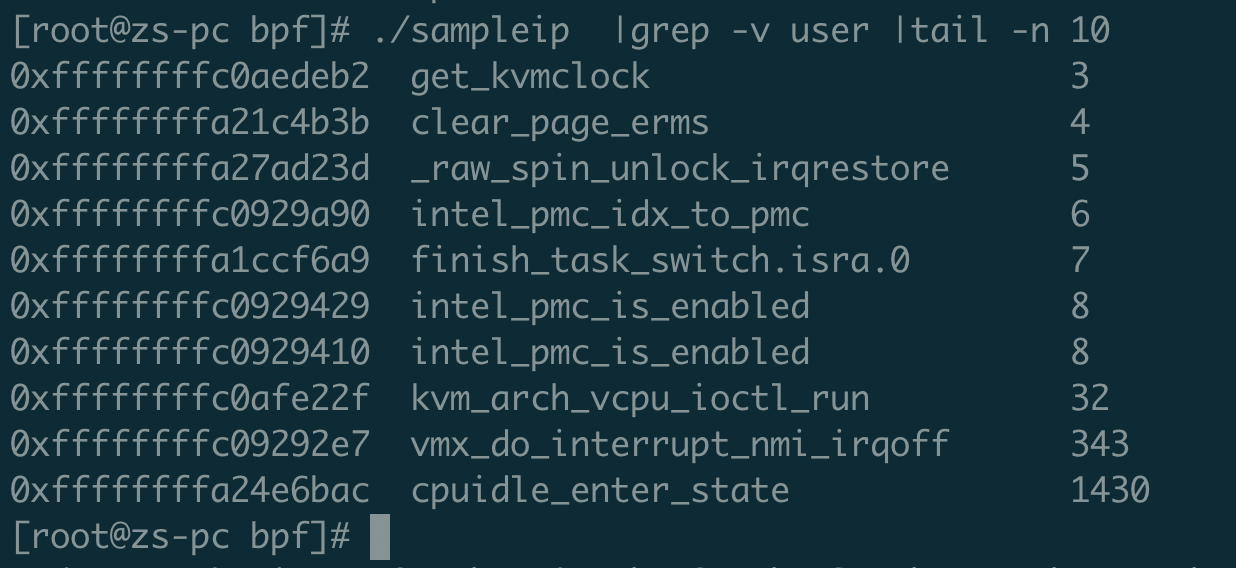
从这个实例中可以看出,开发的eBPF程序比传统的内核开发方便了很多,数据结构不用操心,可以调用的函数也不用操心,都是预先定义好的,只需要实现自己的业务逻辑即可。
eBPF使用场景
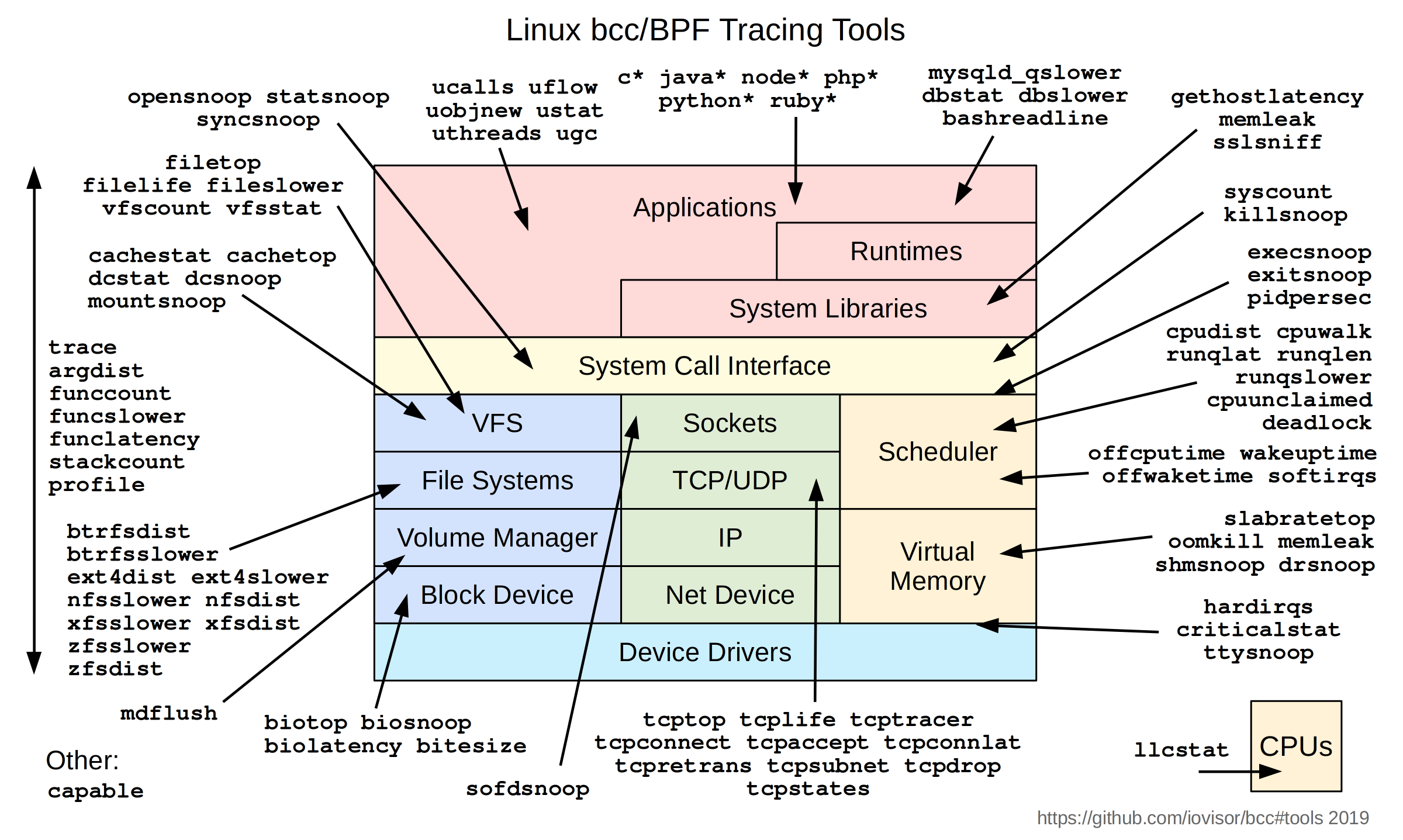
linux性能分析,性能调优上面的sampleip就是简单的内核性能分析,可以看出当前内核经常调用的函数。eBPF对于内核开销很小,可以在生产环境排查问题的时候进行精确定位,同时由于eBPF的安全性,不用担心会把内核搞挂。有兴趣的可以去看一下bcc,里面对于内核每个子系统都有对应的eBPF监控程序,非常方便。
linux网络加速eBPF在这个领域中也是牛的很,底层有XDP快速数据路径,可以直接在网卡收到数据包的同时进行处理,避免内核分配skb开销,可以用来实现DDos,负载均衡,性能媲美DPDK。再往上一点内核的tc也可以hook eBPF程序实现自定义流量分类,再向上的socket层还可以调用eBPF实现动态修改socket选项,甚至tcp的拥塞算法内核也提供了eBPF挂载的地方,可以自己实现一套新的拥塞算法。
安全管理systemd中使用eBPF控制服务可以监听的端口,libvirtd也使用eBPF进行设备的访问控制,社区还有eBPF控制进程允许访问的文件,允许读写哪些/sys文件。
eBPF的出现让Linux内核开发变得简单,降低了内核开发门槛,为普通人了解深入linux内核提供了途径,真的是一个革命性的发明,有linux的地方就有ebpf ^^。